デノイジング拡散モデル (DDPM) に来て, 拡散モデル (Sohl-Dickstein et al., 2015), および Langevin 動力学を用いたデノイジングスコアマッチング (DSMLD) は本質的に等価であることが示された. それらは離散有限ステップでの摂動を考え方の機軸としているが, 本論文においてはそれを連続無限に拡張するという, 確率微分方程式 (SDE) を用いた一般化をみる. 核となる考えは下図にまとめられている.
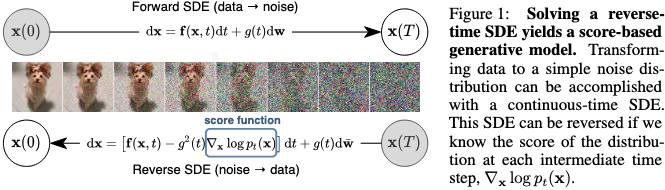
先行研究の整理
— 記法と設計 —
- データ分布: .
- 摂動核: .
- 摂動後分布: .
- 正のノイズスケール列 は狭義単調増加列, , .
- は を満たすくらい十分に小さく, は を満たすくらい十分に大きい.
— 訓練目標 —
DSM の重み付き和.
— サンプリング —
焼きなまし Langevin MCMC.
— 記法と設計 —
- 拡散スケジュール は, を満たす.
- 拡散核:
- 摂動後分布: .
- ノイズスケールは となるように事前に決定される.
- 逆拡散核: .
— 訓練目標 —
ELBO.
— サンプリング —
Ancestral sampling.
SDE を用いたスコアベースモデル
下図がこの枠組みの概念図である.
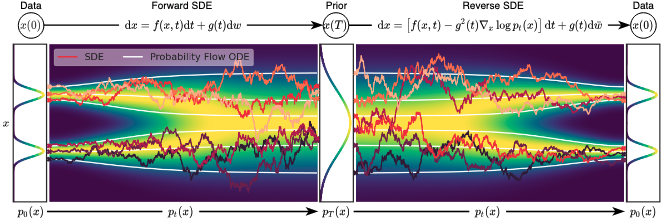
SDE による拡散過程のモデル化
境界条件 (データ分布), および (事前分布) を満たす, 連続時間 を変数とする拡散過程 は次のような It (伊藤) SDE に対する解としてモデル化できる.
ここで, は標準 Wiener 過程 (a.k.a., Brown 運動), は のドリフト係数とよばれるベクトル値関数, は の拡散係数とよばれるスカラー関数である. これらの係数が, および に対し大域的 Lipschitz 条件を満たす限り, It SDE は一意な強解を持つ (Øksendal, 2003).
SDE による逆拡散過程のモデル化
逆拡散過程もまた から へと時間を遡る方向の拡散過程となり, 次の逆時間 SDE でモデル化される (Anderson, 1982).
ここで, は標準 Wiener 過程, は逆向き時間の無限小.
確率フロー ODE
定理. 拡散 / 逆拡散 SDE と同じ周辺確率密度 を軌跡に持つ決定論的 ODE が存在し, それは以下で与えられる. この ODE を確率フロー ODE とよぶ.
証明. 次の最も一般の形式を持つ SDE に対して証明する.
ここで, はドリフト係数, は拡散係数.
周辺分布 の時間発展は次の Kolmogorov 前進 (a.k.a., Fokker-Planck) 方程式で与えられる.
結局これは, という SDE において, とした ODE の Kolmogorov 前進方程式となっている. において, とした特別の場合が確率フロー ODE である.
訓練目標
ここで, は重み付け関数, . 評価のためには遷移核 を求める必要があるが, が Affine 変換ならそれは常に Gauss 分布となり閉形式でかける (Särkkä & Solin, 2019). しかし一般の場合には, Kolmogorov 前進方程式を解かなければならない.
サンプリング
逆拡散サンプラー
逆拡散 SDE の離散化.
予測器 - 修正器 (PC) サンプラー
逆拡散サンプラー (predictor) + 焼きなまし Langevin MCMC (corrector).

確率フローサンプラー
確率フロー ODE の離散化.
これは決定論的ゆえサンプルを早く生成することが可能だが, 結局サンプル品質向上 (離散化誤差軽減) のためには多少のノイズを加えるのがよいとされている.
例: VE, VP SDE, およびその先へ
以上の議論を DSMLD と DDPM に適用する. 得られた 2 つの異なる SDE は, 分散の時間発展性に応じてそれぞれ 分散爆発型 (VE) SDE, 分散保存型 (VP) SDE とよばれる.
VE SDE
DSMLD の 各摂動核 に対応する の分布は, 次の離散 Markov 鎖で与えられる.
, とし, の極限において 1 次近似までをとれば, 連続確率過程 として次の SDE を得る.
そして, 遷移核として次を得る.
また, 逆拡散サンプラー, および確率フローサンプラーとして以下を得る.
- 逆拡散サンプラー
- 確率フローサンプラー
VP SDE
DDPM の 各摂動核 に対応する の分布は, 次の離散 Markov 鎖で与えられる.
, とし, の極限において 1 次近似までをとれば, 連続確率過程 として次の SDE を得る.
そして, 遷移核として次を得る.
また, 逆拡散サンプラー, および確率フローサンプラーとして以下を得る.
- 逆拡散サンプラー
- 確率フローサンプラー
sub-VP SDE
VP SDE の性質を引き継いだ上で, より低分散を実現しようという一工夫.
このとき, 遷移核として次を得る.