生成モデル によって生成されるサンプルを訓練データのサンプルであると, 識別モデル が誤認するように学習を進めていく GAN. 貨幣の偽造者 (counterfeiter) と警察 (police) などのアナロジーから, 発想自体は直感的で理解しやすい.
価値関数 の導入
と による価値関数 のミニマックスゲームが GAN である.
— 記法 —
- データ変数 : 真の分布 によりサンプルされる.
- ノイズ変数 : 事前分布 によりサンプルされる.
- 生成モデル : パラメータ の多層パーセプトロン (MLP) によって表現された, 微分可能な生成関数 により, 生成分布 を出力する.
- 識別モデル : パラメータ の MLP によって表現された, 定値な識別関数 により, が訓練データから来ている確率を出力する.
— ミニマックスゲームの定式化 —
下図がこのミニマックスゲームによる訓練の概要だが, 以下これを理論的に保証する.
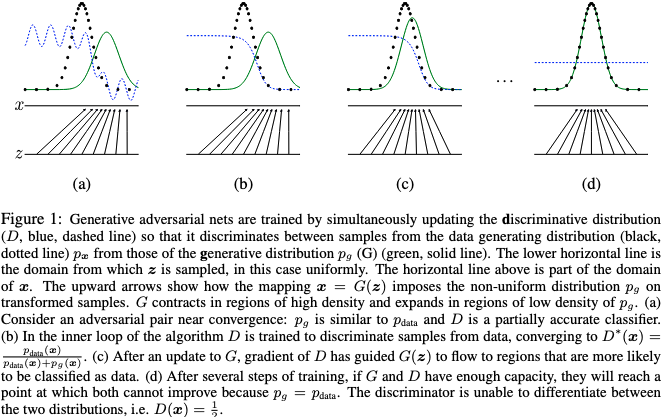
ミニマックスゲームの大域解とアルゴリズムの収束性
ミニマックスゲームによる訓練アルゴリズムが大域的な一意最適解に収束することを示す.
GAN のミニバッチ SGD 訓練アルゴリズム
命題 2 によって収束性が保証される GAN の最終的な訓練アルゴリズム. 実際は を MLP とすると は非凸になるので以下の議論は成り立たないが, それでも実用上うまくいくことが実験結果を見ればわかる. しかし, 非凸性に起因するモード崩壊やミニマックスゲームの定式化に起因する訓練初期の勾配消失などが, GAN による学習の不安定性を招くこともまた事実である.

大域的一意最適解 の存在
定理 1 によりこれを示す (補題 1 は勝手に加えた) .
命題 1. を固定したとき, の最適解は次の表式で与えられる.
証明. 与えられた任意の に対し, の最適化は次の価値関数の最大化をもってして行われる.
一般に, 関数 は において最大値をとる ( の定義域より当然 ). この場合, の外ではサンプルが現れず に寄与しないことから, の定義域をそれらの台の上に限定してよい, , . よって示された.
補題 1. 価値関数を の関数として捉え, とおけば, であり, は に関して凸.
証明. 価値関数の場合, 最大値が存在すればそれは上限と一致するので, . また,
だから, は第 2 項 においてのみ 依存性を持つ. その依存性は,
と に関して線形である. 一方, 第 1 項は 依存性から見れば定数であるから, は についての Affine 関数である. Affine 関数は凸関数, かつ凹関数であるので, これにより補題が示された.
定理 1. が大域的最小値を取るのは のとき, またそのときに限る. そしてその値は である.
証明. 命題 1 により は次のように変形される.
ここで, であり, となるのは のとき, またそのときに限る. したがって であり, 最小値 をとるのは のとき, またそのときに限ることが示された. またここにおいて, 補題 1 より の最適化はいわゆる凸最適化の問題であることが示されたため, 最適化されたときにとる最小値は必ず大域解となる. 以上により示された.
アルゴリズム 1 の収束性
命題 2. 次の 3 つの仮定の下で, アルゴリズム 1 により は に収束する.
- と が十分な容量を持つ.
- アルゴリズム 1 の各ステップで, 与えられた に対し, はその最適解に到達することが可能.
- それを受けて, は を最適化するように更新される.
証明. 一般に, 凸関数 の上限の劣微分は, 最大値をとる点においてその関数の微分を含む, , . したがって は に関して凸 (補題 1) であるから, 次が成り立つ.
つまり左辺による最適化は右辺による最適化によっても達成される. ゆえに仮定 1-3 のもと, アルゴリズム 1 により は へと収束する (定理 1).