拡散モデルの原型となる論文. 表題の通り, 非平衡熱力学を下敷きにしており, 情報科学への応用, および定式化, 最終的な実装までをもやってのける強力な知性に驚嘆する. 美しいことにモデルの枠組みも非常に簡明で, 以下 2 つの双対的な過程より構成されている.
- 拡散過程: 所与の複雑なデータ分布から Gauss 分布や Laplace 分布などの単純な分布への変換, Fig. 1 でいえば, 青 () から 青 () への変換.
- 逆拡散過程: 単純な分布から所与のデータ分布を再現しようとする変換, すなわち生成過程, Fig. 1 でいえば, 赤 () から 赤 () への変換.
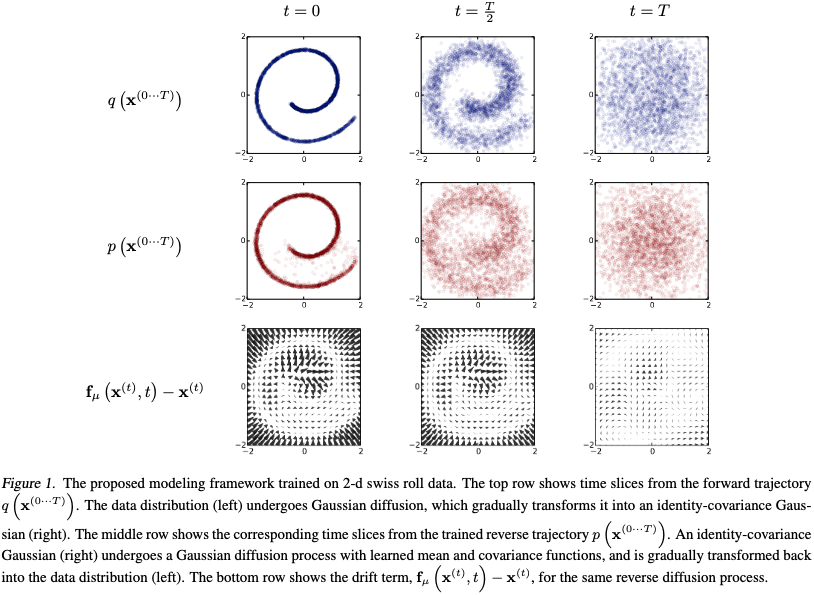
拡散過程の軌跡
拡散過程は, “データ分布 が, 単純な分布 に対する Markov 拡散核 (ここで は拡散率) を繰り返し適用されることで, 段々と に変換されていく過程” として, 次のように定式化される. ただし, 核のパラメータは多層パーセプトロンにより調整される.
またその軌跡は, 拡散を ステップ行うとすれば, 次のような Markov 連鎖として与えられる.
逆拡散過程の軌跡
拡散過程の定式化を振り返れば, 逆拡散過程の軌跡が として, 次のように与えられることは自明といってよい.
生成分布
逆拡散過程を通じて最終的に得られる生成分布は以下で与えられる.
近似のない式変形を行ったが, 各段階でそれぞれの式の表す意味は大きく異なる. においては, の規格化定数が計算不能ゆえ, 積分も計算不能であった. しかし において, 焼きなまし重点サンプリング (AIS), ないしは物理的な視点から Jarzynski 等式の発想により, 規格化定数は拡散過程と逆拡散過程の比として現れるようになった. そして最終的に, 拡散率を とする極限, すなわち統計力学的な見方では準静的過程とよばれる過程を考えることで, その比すらも消失した. ここにおいてはもはや積分計算の際に, Monte Carlo 法による多数サンプリングを必要とせず, から単一サンプリングするだけで結果を導けるようになった.
訓練
訓練とは, 次で与えられる対数尤度 を最大化することである. しかし実際の問題は, その下限 を最大化する逆拡散過程を見つけることである, , .
K を解析的に計算可能な形へ書き換える
— のエントロピー を導入 —
— におけるエッジ効果を除去 —
と考える.
最後の変形は拡散核を適切に設計していれば, に対する の交差エントロピーが と考えられることによる.
— 事後分布 に着目 —
拡散過程は Markov 過程なので, 条件に が入ったところで影響はなく以下が成り立つ.
したがって は次のように書き直せる.
第二の分布 の導入
十分滑らかな の導入により, 摂動として外部情報を取り込むことで, 理論の軽微な修正のみで事前分布 の再現を超えた柔軟な生成タスクを可能にする. ただし, の導入によっても閉形式となれば, 当然摂動近似によらず厳密計算が可能である.
修正逆拡散分布 を第二の分布を導入して次のようにかく.
さらに, 修正 Markov 逆拡散核 を用いれば次のように書き直せる.
したがって, 修正逆拡散過程は以下のようにかける.
逆拡散過程のエントロピー
は解析的に計算可能な上界, および下界によって評価可能である. この評価は逆拡散過程の精度を測るうえで重要である. Bayes の定理により以下の不等式を得る.